[DB] INDEX SEEK 정리
[DB] MSSQL Index Seek
Index Seek란?
일종의 Non-Clustered Index를 인덱스 트리를 타고 원하는 데이터로 바로 접근한 경우입니다.
일반적으로 Non-Clustered Index는 Dense Index이고, Secondary Index입니다.
- *Index : 검색의 효율성을 높이기 위한 물리적인 데이터 구조
- *Sparse Index : 해당 레코드 존재 페이지를 가리키는 포인터를 저장합니다.
- *Dense Index(Secondary Index) : 해당 레코드를 가리키는 포인터를 저장합니다.
select * from TableA
where colA in ('B105', 'C101')
-- colA에 Non-Clustered Index가 생성됩니다.
-- Clustered Index는 생성되지 않습니다.
-- 이 쿼리는 실제 실행에서 Index Seek를 한다고 가정합니다.이 쿼리문을 처리하는 과정은 다음과 같습니다.

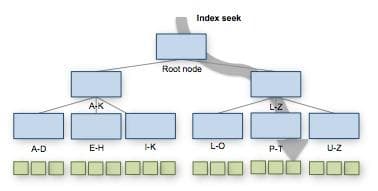
SQL Server는 'B105'를 찾기위해서 동작하고 이 동작을 Index Seek라고 부릅니다.
- Root Page를 통해서 Index Page를 찾습니다.
- Index Path에서 Data Page를 찾아, 해당 Row를 읽습니다.
다만 이 경우 Unique Index인지, Non-Unique Index인지에 따라 페이지를 읽은 수가 다릅니다.
- Unique Index 인 경우, 3Page를 읽습니다.(Index Page = 2, Data Page = 1)
- Non-Unique Index 인 경우, 한 페이지를 더 읽어야합니다. ('B105' 다음이 있는지 확인해야 마지막인 것을 확인할 수 있으므로)
다만, 핵심 중 하나는 적은 Row 수를 가지는 경우에서는 Index를 생성하지 않는 것이 좋습니다. 그 이유는 CPU 비용이 Index Seek 보다 Full Scan이 더 적기 때문입니다. (Index Seek 보다는 Data Page를 처음부터 끝까지 읽어서 필요한 부분을 읽는 것이 더 좋습니다.)
Index Scan과 Index Seek 의 차이
- Index Scan : 해당 테이블의 컬럼을 모두 찾습니다.
- Index Seek : 해당 인덱스를 바로 찾아갑니다.
이와 같이 Seek가 일반적으로 Scan보다 비용(cost)이 적게 드는 것을 확인할 수 있습니다.
출처
